
Verzamelingen van omzendbrieven van Ministerie van Justitie
Statistisch jaarboek voor België en Belgisch-Kongo
Welke zoekwoorden gebruiken?
OCR (Optical character recognition) of optische
tekstherkenning biedt heel wat nieuwe mogelijkheden bij de
raadpleging van archiefdocumenten. Door middel van een eenvoudige
zoekrobot kan u immers onmiddellijk zoeken naar de woorden in de
tekst en hoeft u niet meer om te gaan via de archivistische
beschrijving. De keuze van de zoekwoorden is echter cruciaal. Te
algemene zoekwoorden zullen u
een overvloed aan hits opleveren maar te gespecialiseerde of niet
aangepaste zoekwoorden kunnen verkeerdelijk de idee geven dat een
bepaald thema niet behandeld is in de doorzochte documenten.
Idealiter neemt u eerst een aantal teksten uit het betreffende
archiefbestand door om u de gebruikte terminologie eigen te maken en
op die manier gerichter te kunnen zoeken.
Kwaliteit van de tekstherkenning
De laatste jaren is de technologie zeer sterk verbeterd zodat ook teksten die enkele jaren geleden onvoldoende resultaat opleverden vandaag met een vrij grote nauwkeurigheid kunnen herkend worden. Veel blijft natuurlijk afhankelijk van de kwaliteit van het oorspronkelijke document en van het gedigitaliseerde document.
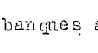 en
en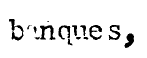 wordt
bij voorbeeld correct herkend als 'banques'
wordt
bij voorbeeld correct herkend als 'banques'
![]() werd ook correct herkend als 'émission'
werd ook correct herkend als 'émission'
![]() daarentegen werd niet correct herkend.
daarentegen werd niet correct herkend.
Het Rijksarchief beperkt zich tot tekstherkenning van gedrukte en getypte teksten. Het proces voor tekstherkenning van handgeschreven documenten is te arbeidsintensief in vergelijking tot het resultaat. De tekstherkenning wordt automatisch uitgevoerd en wordt niet manueel gecontroleerd of nabewerkt. Evenals tekstherkenning van handgeschreven teksten is deze controle te arbeidsintensief. De full-text research optie is dus een extra zoekmogelijkheid die u wordt aangeboden maar die het systematisch doornemen van archiefbestanden niet vervangt.
Wat zie ik op scherm? Waarom worden de woorden niet aangeduid in de tekst?
Gezien de mogelijke fouten in de OCR wordt u op scherm een digitaal beeld van het oorspronkelijke document aangeboden in de vorm van een pdf-document en wordt de 'tekst' in een onderliggende laag bewaard. De pdf-documenten vormen samen een eenheid: één archiefnummer, een verslag van een vergadering, een aflevering van een tijdschrift, ...
Bij het aanklikken van het pdf-document wordt de door u gezochte woorden in de tekst aangeduid. Deze laatste optie heeft echter een aantal beperkingen. Bij het samenvoegen van de lagen worden in het pdf-document soms extra blanco's toegevoegd om de beeldlaag en de tekstlaag zo goed als mogelijk boven elkaar te leggen. Deze blanco's zorgen er echter voor dat de gezochte woorden niet meer aangeduid worden. Indien u dus de mededeling krijgt dat het zoekwoord niet voorkomt, kan u de tekst doorlopen of de zoekactie manueel herstarten door het toevoegen van één of meerdere blanco's tussen de letters.